MySQL
MySQL索引与底层结构
底层数据结构
内容读取
JAVA 调度cpu,读取RAM内容,RAM从硬盘以页的形式载入,页再载入的内存之中,一次从磁盘中读取的数据为页的整数倍,但页与页之间会存在缺页中断,因此在数据库存储中定一个一个节点为一页, 一页默认大小为4k
索引
帮助MySQL高效获取数据的排好序的数据结构;索引存储在文件里
磁盘存取:寻道时间(速度慢,费时)+旋转时间(速度较快) 寻道时间即磁头移动时间,磁道 旋转时间即扇区上寻址; kafka的优化,大部分数据存取都是在落在旋转上,速度快
索引结构
可以认为一个节点的操作就伴随着一次IO
二叉树 容易单边树过深,特别是在数据库自增主键的情况下,和顺序查找没有区别,时间复杂度是一样的
图示
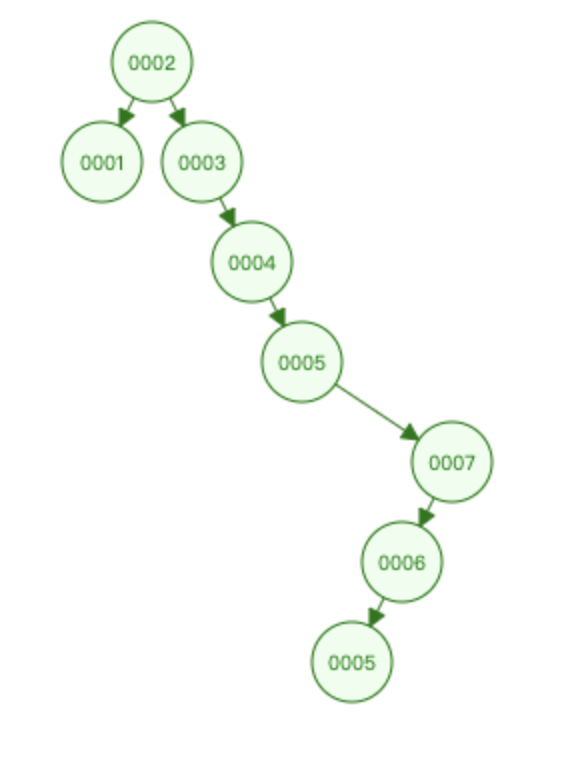
红黑树 随着数据的增多,其深度h越深,不可控
图示
HASH 根据hash值分配变量地址,进行存储,可以快速寻找到某一个变量值,但不适用于范围查找
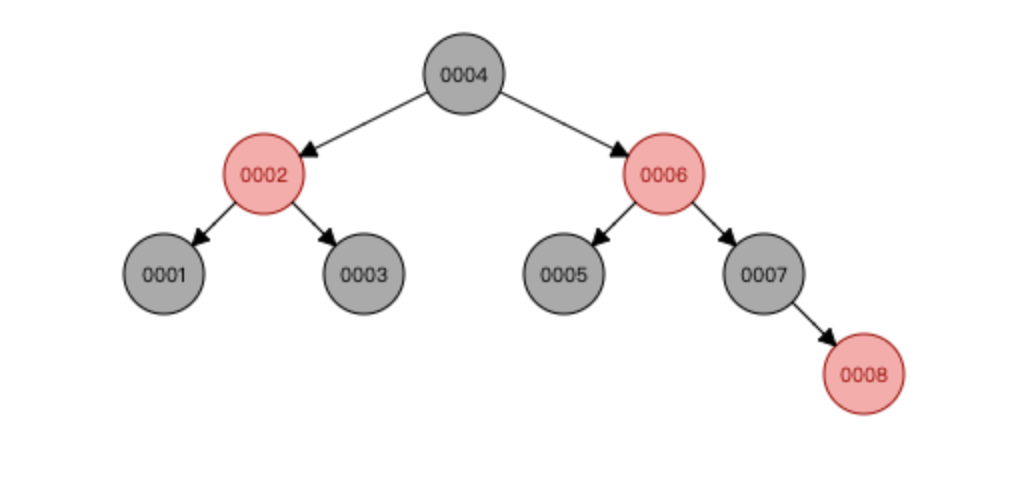
BTREE 相较于红黑树 其宽度增长,对应的纵向深度h可控
度(Degree) 节点的数据存储个数 定义度为4 其实并不会存储达到度的个数,达到一定阈值自然会延伸叶节点
叶节点具有相同的深度
叶节点的指针为空
m节点中的数据key从左到右递增排列
图示
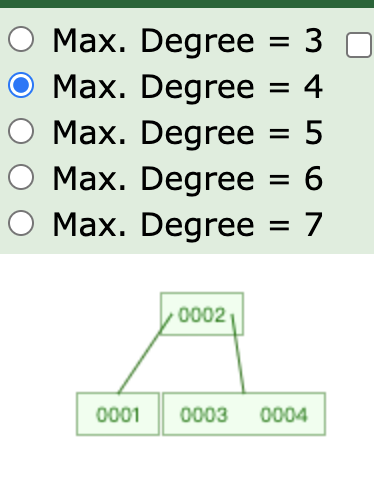
底层存储结构 B+Tree(B-Tree变种) 非叶子节点不存储data,只存储key,可以增大度 叶子节点不存储指针 顺序访问指针,提高区间访问的性能
图示
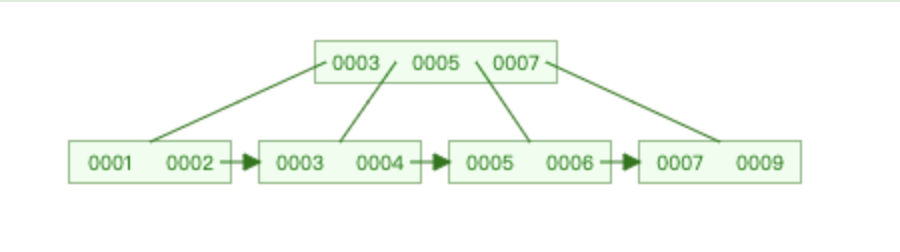
将数据挂载在叶子节点上,不影响查询效率,叶子节点本身已是最后一次查询了
区别B-Tree,有指针指向下一个节点,方便范围查询
性能分析 一般使用磁盘IO次数评价索引结构的优劣
预读:磁盘一般会顺序向后读取一定长度的数据(页的整数倍)放入内存
局部性原理:当一个数据被用到时,其附近的数据也通常会马上被使用
B+Tree节点的大小设为等于一个页,每次新建节点直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,就实现了一个节点的载入只需一次I/O
B+Tree的度d一般会超过100,因此h非常小(一般3到5之间)
存储引擎 MyISAM
索引文件与数据文件是分离的
表锁
索引实现非聚集 主键索引图示 叶子节点存放指针
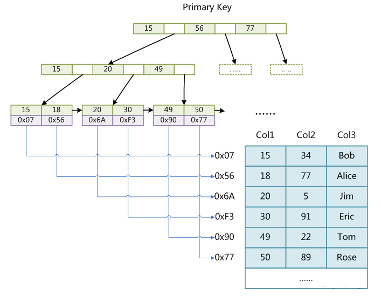
非主键索引图示 与主键索引一样
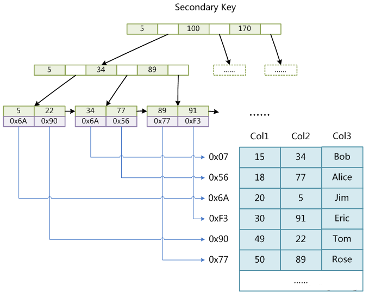
InnoDB
行锁
数据文件本身就是索引文件
表数据文件本身就是按B+Tree组织的一个索引结构文件
聚集索引-叶节点包含了完整的数据记录
图示
为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?
B+Tree的生产依赖于某个数进行比较,生成两边,在未定义主键的情况下会在后台默认创建一个主键。但不建议这么做,从可维护性及易读性上考虑,都应该显示指定
使用整型:方便数的比较
自增:有利于在叶子节点生成连续的物理块,便于数据存储是连续的
为什么不建议用UUID生成主键?
非整型,存储底层会使用ASCII码比较,耗时长于整型
数据占用空间大于整型,因此一个节点能容纳的数据即度小于整型存储的
最主要的,无法形成自增,其在插入数据的时候,要寻找其uuid的两边值并插入其中,导致叶子节点需要重新演化生成。极大的插入影响效率。
注意:分表使用的雪花和基因算法,都是维持一种上升的趋势的
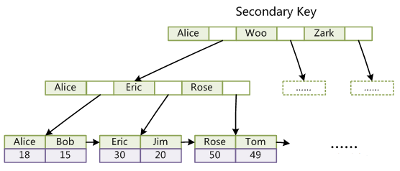
为什么非主键索引结构叶子节点存储的是主键值?
维护数据的时候,只需要维护一份
节省空间
SQL底层执行原理
关注my.cnf
连接 session load权限 并 缓存,此时修改数据库用户权限,也不会立马反馈。 默认长链接 8h。
show processlist 查看连接进程号,kill id 号
server缓存层 适合 几乎不变动的表数据
引擎层 会存储热点数据 bufferpool 缓存 采用 LRU
antlr4 分库分表 分布式 rollback
binlog建议 row; statement可能导致主从不一致 update … set where a=xx or b=xx limit 1
MySQL设计原则
建表规约
- 代码先行,索引后上
- 一般主体业务功能开发完毕,把涉及到该表相关SQL都要拿出来分析之后再建立索引
- 命名规范 表名、字段名、索引名 参考《阿里巴巴Java开发手册》
数据类型
- 确定合适的大类型:数字、字符串、时间、二进制;
- 确定具体的类型:有无符号、取值范围、变长定长等
- 尽量把字段定义为NOT NULL,避免使用NULL。
说明:若为少数数据,可不使用isNull判断,通过程序过滤
具体细则
- 如果整形数据没有负数,如ID号,建议指定为UNSIGNED无符号类型,容量可以扩大一倍。
- 建议使用TINYINT代替ENUM、BITENUM、SET。
- 避免使用整数的显示宽度(该宽度只是0填充适用),也就是说,不要用INT(10)类似的方法指定字段显示宽度,直接用INT。
- DECIMAL最适合保存准确度要求高,而且用于计算的数据,比如价格。但是在使用DECIMAL类型的时候,注意长度设置。
- 建议使用整形类型来运算和存储实数,方法是,实数乘以相应的倍数后再操作。
整数通常是最佳的数据类型,因为它速度快,并且能使用AUTO_INCREMENT
- 建议用DATE数据类型来保存日期。MySQL中默认的日期格式是yyyy-mm-dd
当数据格式为TIMESTAMP和DATETIME时,可以用CURRENT_TIMESTAMP作为默认(MySQL5.6以后),MySQL会自动返回记录插入的确切时间
TIMESTAMP是UTC时间戳,与时区相关。
DATETIME的存储格式是一个YYYYMMDD HH:MM:SS的整数,与时区无关,你存了什么,读出来就是什么。
- 字符串的长度相差较大用VARCHAR;字符串短,且所有值都接近一个长度用CHAR。
CHAR和VARCHAR适用于包括人名、邮政编码、电话号码和不超过255个字符长度的任意字母数字组合。那些要用来计算的数字不要用VARCHAR类型保存,因为可能会导致一些与计算相关的问题。换句话说,可能影响到计算的准确性和完整性。
- 尽量少用BLOB和TEXT,如果实在要用可以考虑将BLOB和TEXT字段单独存一张表,用id关联。
索引规约
核心思想
- 尽量利用一两个复杂的多字段联合索引,抗下你80%以上的查询,然后用一两个辅助索引尽量抗下剩余的一些非典型查询,保证这种大数据量表的查询尽可能多的都能充分利用索引,这样就能保证你的查询速度和性能了!
- 业务上具有唯一特性的字段,即使是组合字段,也必须建成唯一索引。
- 联合索引尽量覆盖条件
比如可以设计一个或者两三个联合索引(尽量少建单值索引),让每一个联合索引都尽量去包含sql语句里的where、order by、group by的字段,还要确保这些联合索引的字段顺序尽量满足sql查询的最左前缀原则
- 不要在小基数字段上建立索引
索引基数是这个字段在表里总共有多少个不同的值。例:性别 男或女 基数为2
- 尽量对基数较大的值添加索引,才能发挥b+tree的优势来
- 长字符串可以采用前缀索引
- where与order by冲突时优先where
因为大多数情况基于索引进行where筛选往往可以最快速度筛选出你要的少部分数据,然后做排序的成本可能会小很多。
- 一般范围查找的条件都要放在最后
- 定时任务刷某些字段值 例如:判断用户最近7天是否活跃 不要根据时间字段,而是通过记录标识